AI/DS Conference 2017: Amazing GANs

今年分別在 PyConTW 2017 及人工智慧年會講了關於生成式對抗網路的題目。在人工智慧年會前檢查舊的投影片,覺得有些想法已經改變,所以決定重做一份。做投影片的過程很麻煩,但是為了能夠流暢的說出自己的想法,我需要檢視每個細節,也因此對這個題目有更多的瞭解。
I had a talk about Generative Adversarial Networks in AI/DS Conference 2017. Although I had done it once in PyConTW 2017, it’s still tough for me. Considered the difference between the 2 conferences, I made a bold decision to prepare a new slide. It was not easy, but I learnt more. Now I am doing it again by publishing the materials online.

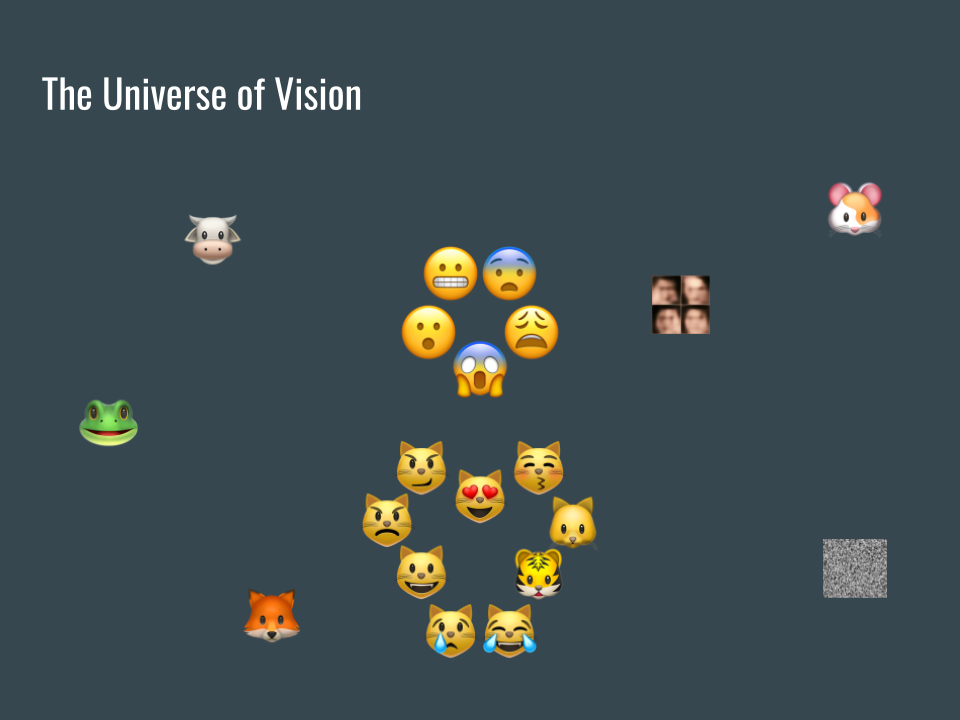
假設有一個空間涵蓋所有圖片,在這個空間裡有很多圖片像貓臉、表情符號、狐狸跟老鼠。也包括沒有意義的圖片,比如雜訊。
Assume there is a space that contains all visible images. We can find many images familiar to us there. Include cat faces, emoji icons, foxes and rats. Images we can not recognize also exist here.

現在我們想知道貓臉是什麼樣子,照上一頁對圖片空間的想像,所有的貓臉應該會集中在一個區域裡,我們用虛線來標示這個區域。
Now we want to know what cat face looks like. According to the imagination of the vision universe, all cat faces are in a sub-domain inside the universe. We use a dot line to enclose this cat face area.

接著我們收集各式各樣的貓臉,試圖找出這些貓臉的共同特徵。但是因為圖片太多了,不可能收集到所有的圖片,也就是這個子空間不會被填滿。
Then we collect cat face images as many as possible and try to find general features between those cat faces. However, there are too many possible images so it’s impossible to fill this sub-domain.
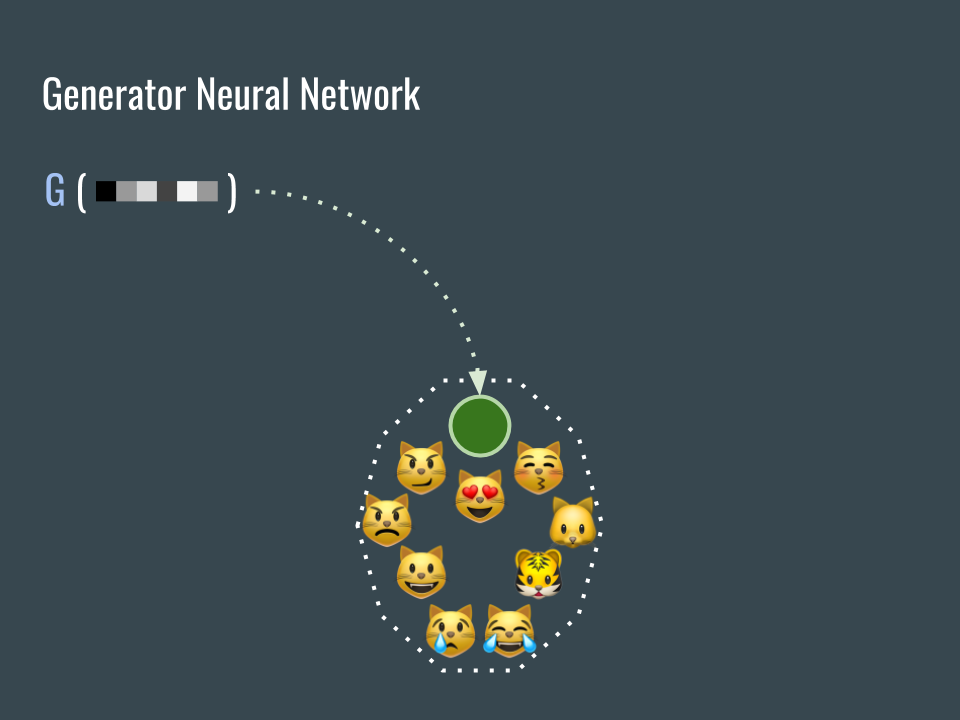
我們建立一個可以產生圖片的網路 G,並且希望產生的圖片是貓臉。為了訓練這樣的網路,最終需要一個判定貓臉的標準做為損失函數,問題是在如何建立這個標準。
We build a neural network G to generate cat face images. In order to train this convolutional neural network, we need a loss function. The problem is: how can we tell if images are cat faces?
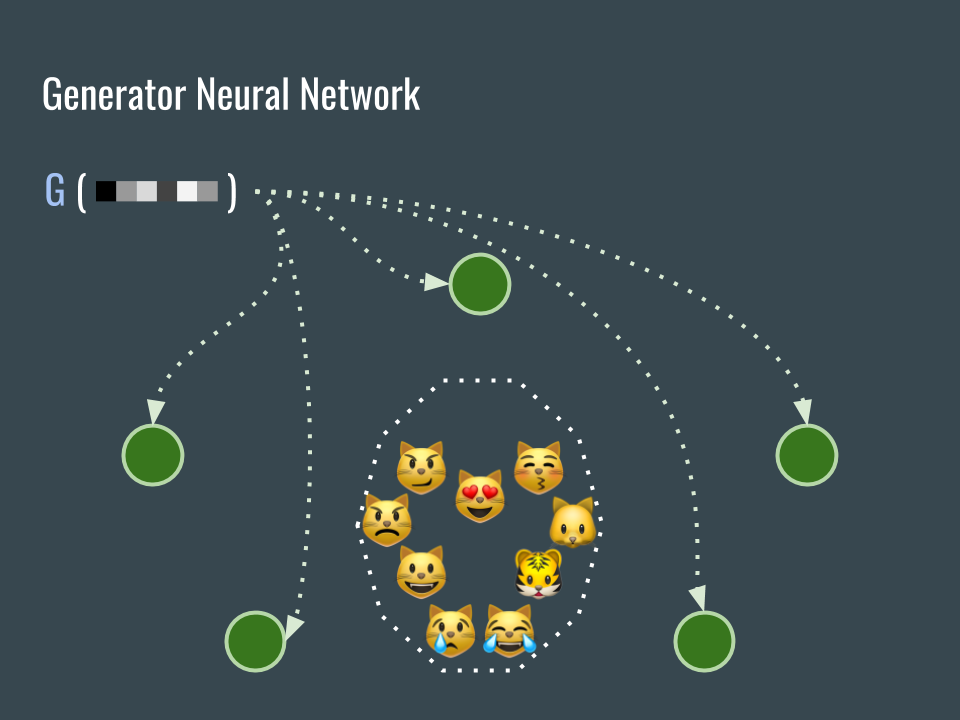
因為剛開始的時候網路 G 未經訓練,所以產生的圖片會散落各處。
Because this convolutional neural network G is just initialized, so it can not generate meaningful images.
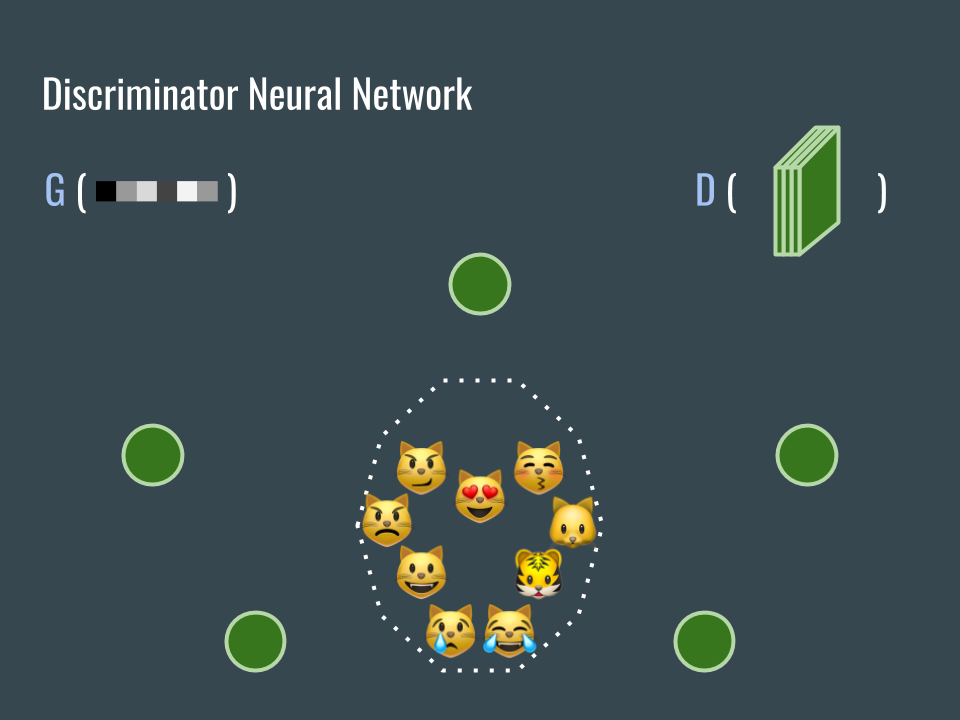
為了訓練網路 G (我們還不知道 G 的損失函數是什麼),建立另一個網路 D。
In order to help the G network (we do not know about the loss function of G yet), we build another D network.
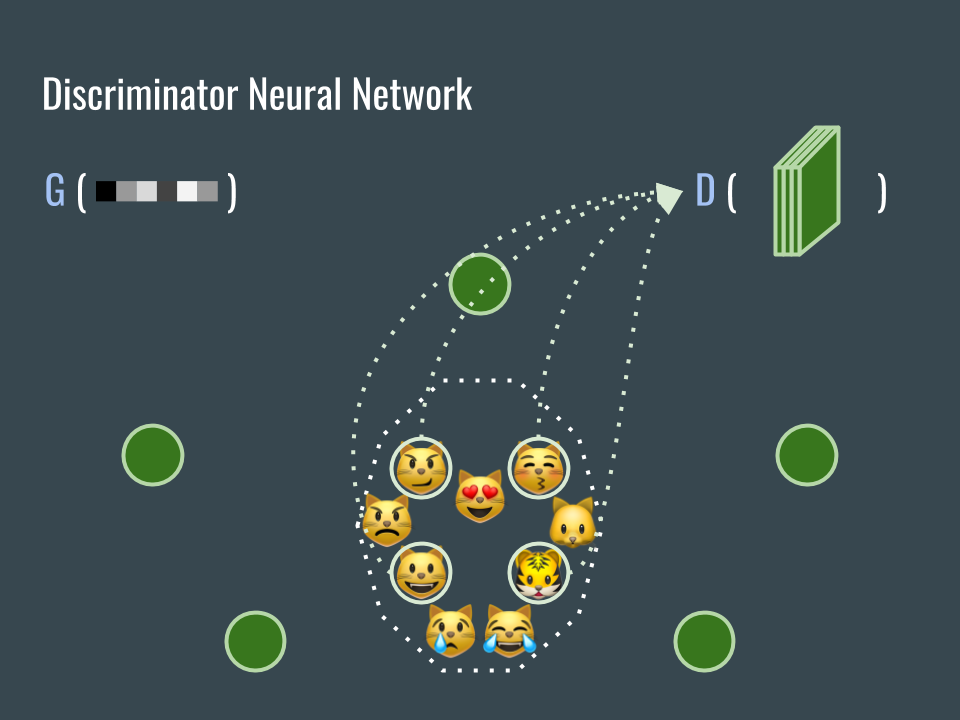
D 網路的任務是協助我們判斷圖片是不是貓臉。用已經收集到的大量貓臉圖片來訓練這個網路,而且這些圖片的標籤都是真(因為都是貓臉,這個部份一直讓我覺得生成式對接網路不是完全的非監督式學習)。
We want the D network to help us classifying if images are cat faces. Fortunately, we have collected lots of cat faces. Use those images to train the D network and tell D network that all those collected images are real (Because they are cats. For this reason, I keep think that GAN is not 100% unsupervised learning).
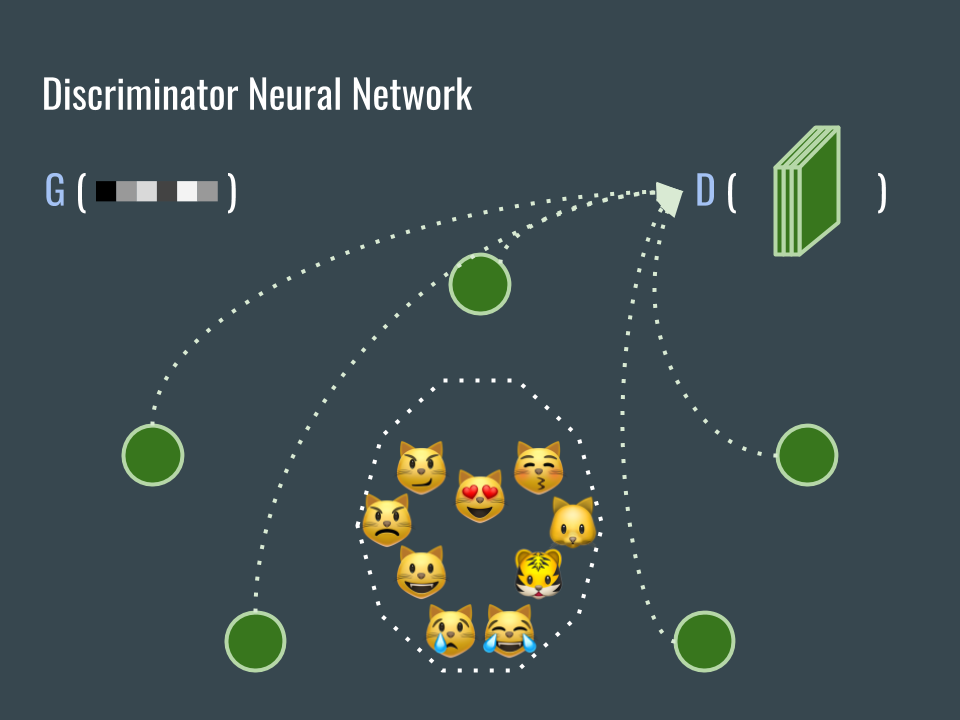
接著用 G 網路產生一些圖片,把這些圖片也用來訓練 D 網路,這些生成的圖片的標籤都是假。
Then we also use the images generated by G network to train D network. All the images from G are fake (cat faces). The mission of D is to classify if an image is real (collected) or fake (generated) cat face.
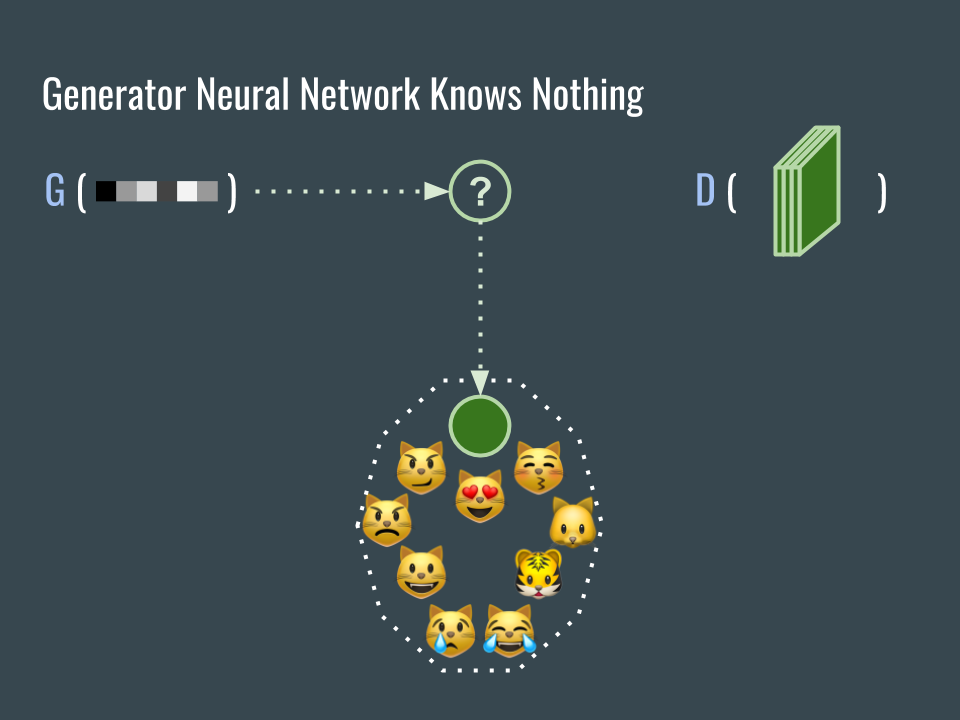
G 網路的任務是產生落在貓臉空間的圖片,但是該怎麼做呢?
The mission of G is to generate cat face images, but how?
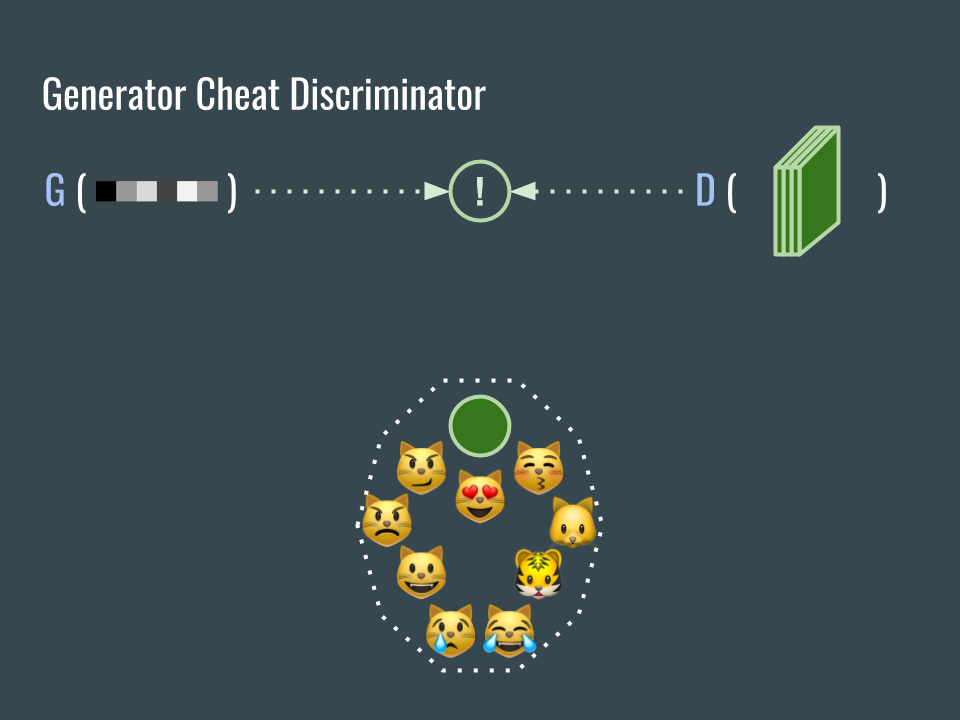
現在我們有兩個互相對抗的網路了:
- G 網路的目標是欺騙 D 網路,讓 G 所產生的圖片通過 D 的考驗(被當真)。
- D 網路的目標是識破 G 網路,讓 G 所產生的圖片通不過 D 的考驗(當假)。
We have 2 networks against each other, and that’s why it’s adversarial.
- generator want to generate images that can fool discriminator. The loss is how much does the discriminator think the generated images are fake.
- discriminator want to tell generated images are fake.

我們該如何訓練這兩個網路呢?在初始化兩個網路後,所有由 G 產生的圖片都會離貓臉空間很遠。我們用藍色色塊來表示 D 標示的範圍,虛線內為真,虛線外為假。
How can we train the 2 networks? After initialization, all images generated by G are far away from real-cat-face-sub-domain. We use the blue area to represent real part of D. And G does not know what is cat face.
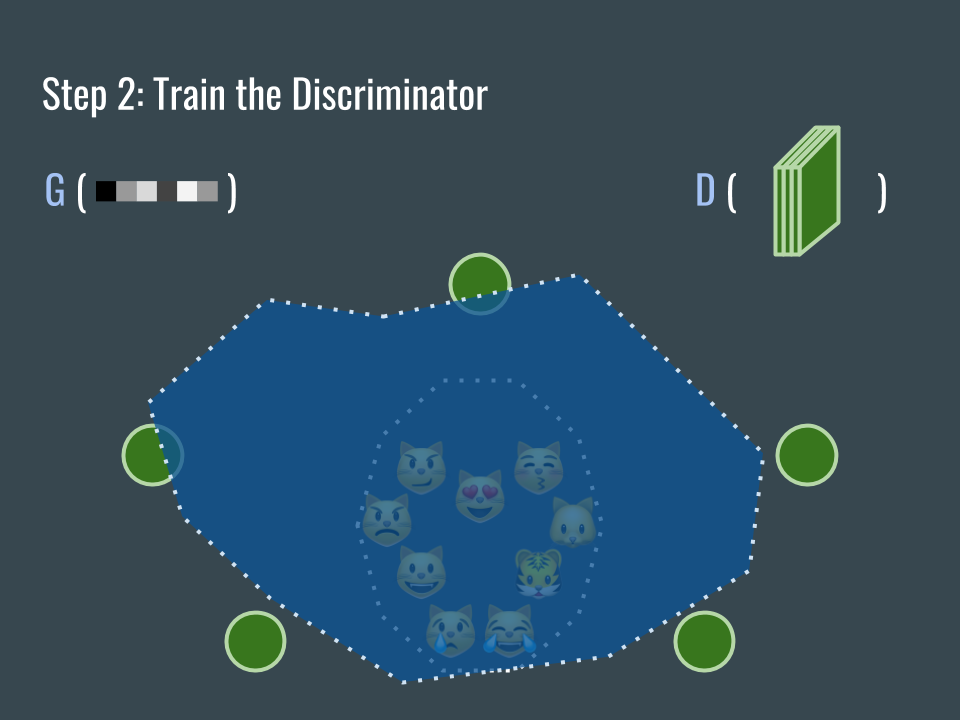
用一些 G 產生的圖片跟收集來的圖片稍微訓練一下 D,D 網路開始能大致分辦圖片的來源。
Let’s first train the discriminator a little bit (with generated and collected images). By slightly adjusting the weights of D, it can almost tell if the images (green circles) are generated.
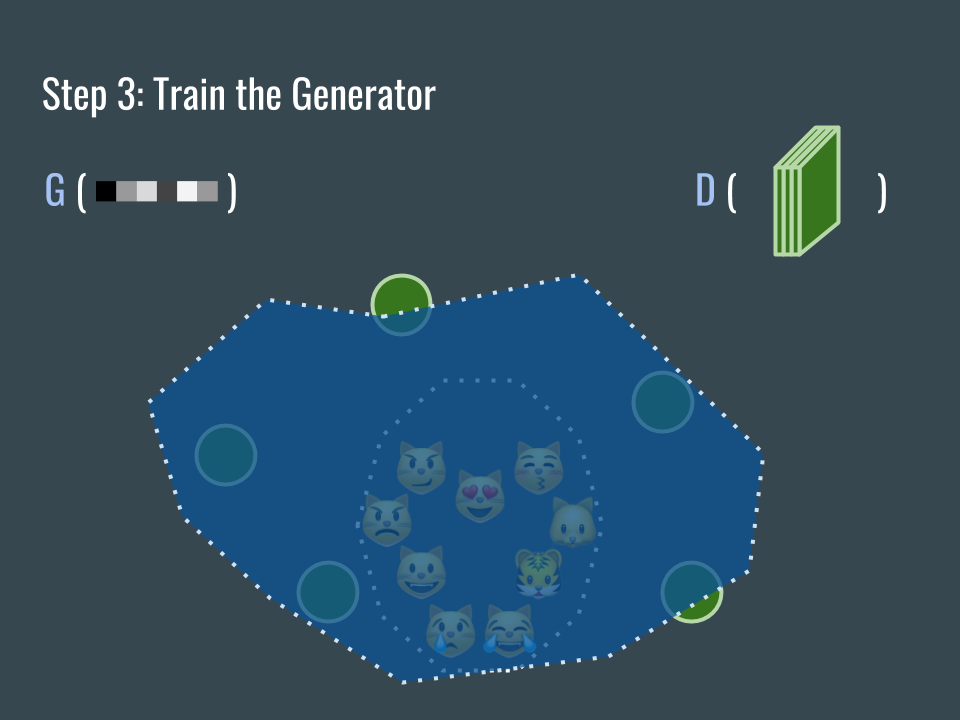
接著訓練 G 網路,讓 G 產生的圖片(綠色的圓圈)向藍色區域靠近。
Then it’s generator’s turn. Adjust its weights a little bit so that the generated images (green circles) are moving toward the blue area.

接著繼續訓練 D 網路,讓 D 網路再次能分辦圖片的真假。
Train the discriminator again. Make D great again.
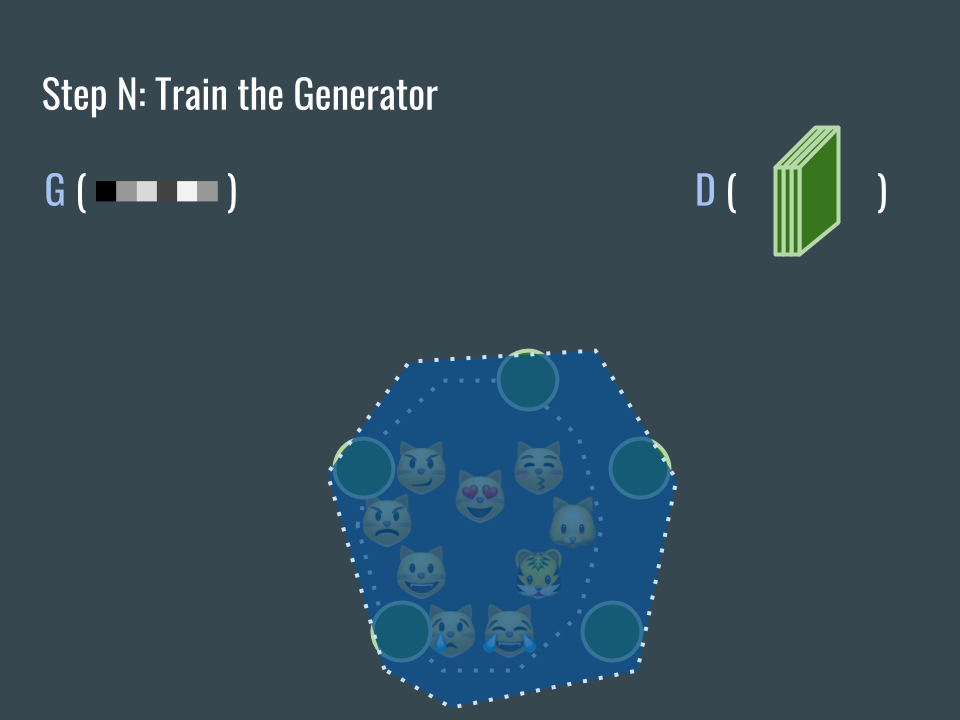
重復這個步驟。
Repeat the process.

再重復這個步驟。
Repeat the process.
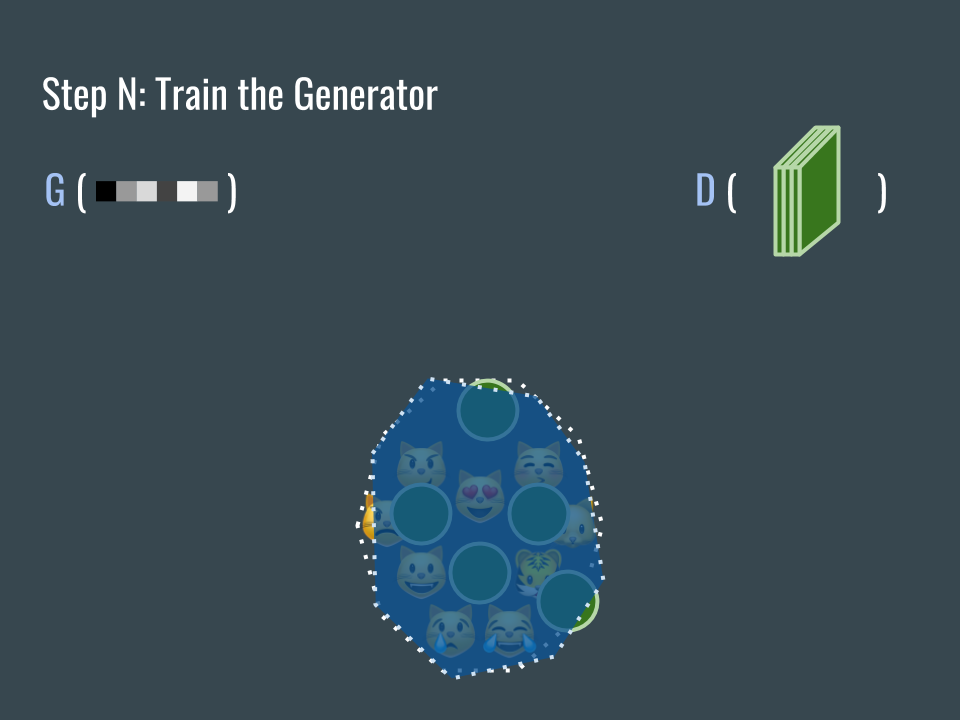
一直重復這個步驟。最後 D 標示的藍色區域會大致覆蓋貓臉空間,而 G 產生的圖片會落在 D 標示的區域裡。
Repeat the process. Now the blue area almost covers the cat face sub-domain while the generated green circles are inside the blue area.
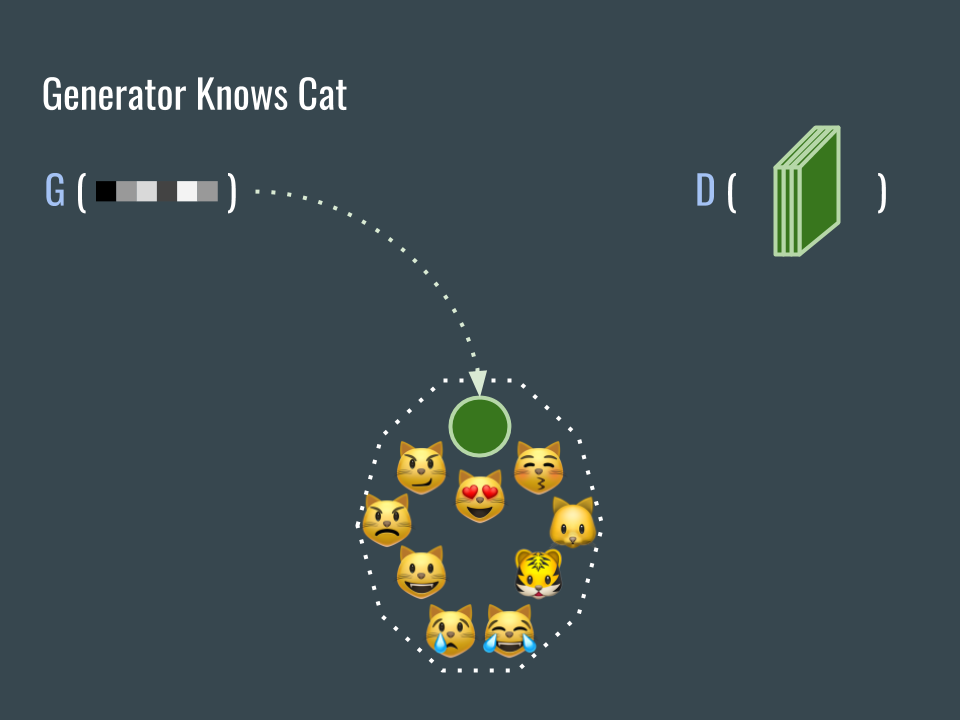
這時候的 G 網路已經知道貓臉的樣子,任務完成!
Now the trained generator can generate images that look like cat faces. Mission complete! The generator knows about cat faces.
有些說法(我剛開始也是)認為 G 可以用來增加訓練資料,但這並不一定是對的。G 能產生的資料還是受限於已經收集到的資料,回到上面的投影片,如果貓臉區域的上半部沒有被收集到並用來訓練 D ,那 D 就會把該區域的圖片當作是假的,而 G 也因此不會產生那樣的圖片。
Some people, included me, think that the generator can generate more data for the other training. However, it is not always true. What the generator can do is to generate images inside the collected-data-sub-domain, it is constrained by the dataset. Consider the dot line that enclose the collected cat faces. If the images in the top-half part are never collected. Then the D network would just classify them as fake and G would not generate images outside the area.