DQN and OpenAI Cartpole
The beginning of a great journey
I am curious about what is neural network and want to know what can be accomplished with this algorithm. I have explored many online resources but could not understand even why ReLU works (I still do not understand it, but I can guess now). Then I found CS231n on YouTube which taught how researchers tackle vision problems with neural networks. I like the course and will recommend it to whoever want to explore this area. I found it in May and have gone through all video lectures and assignments. Andrej Karpathy is really good at teaching. I read some of his blog posts and found OpenAI Gym, started to learn reinforcement learning 3 weeks ago and finally solved the CartPole challenge.
OpenAI Gym is a reinforcement learning challenge set. As its’ name, they want people to exercise in the ‘gym’ and people may come up with something new. For me, it’s like an interesting puzzle collection. I have to learn something new if I want to solve them. I started to go through RL course by David Silver and try to attack CartPole challenge v0.
What is Q and what is Q-Learning
A reinforcement learning problem is about states, rewards, and actions. We want to attack this kind of problem by implementing an agent. Tell the agent current environment states and what he got when reaching this state. Then the agent makes a decision, the action, base on what he have learned so far. Imagine you are a cat agent and sit by your slave (current state), you make sound ‘meow’ (a random action) then the slave gives you a massage (the reward). You feel good and ‘meow’ again and again (take action base on what you have learned). Then you feel boring suddenly and try to give the slave a touch (different action) and got a special massage. Q is what you will get by taking action on certain state. Q-Learning is to learn a function which tells us the reward by taking different action in certain states. More precisely, we try to solve this equation:
r is the immediate reward. $\gamma$ is the discount factor. $Q(s, a)$ means the value of taking action $a$ in state $s$. The equation means the value of taking action $a$ at state $s$ is the immediate reward r (of taking $a$) plus the value of taking best action at its’ next state. By update this equation repeatedly, we will get a better $Q$ and find the best action for the current state.
$\gamma$ is the most confusing factor for me in the beginning. Typically it’s a scale value between 0.0 and 1.0. 0.0 means we want only the immediate reward (r) and do not care what will happen after the action. 1.0 means we want the future reward as good as possible. However, we usually do not use 1.0. In the cart pole challenge, we want the pole stands there as long as possible, so I choose 0.95.
The deep Q-Learning network
Now we know the goal, but how can we find the Q? This is where the neural network is involved. We’ll build a neural network which takes a state as input and output value of each possible action. Ideally, the pole is always in a state that we can map to action-value pairs. In each step we pick the action with the highest value and the goal should be accomplished.
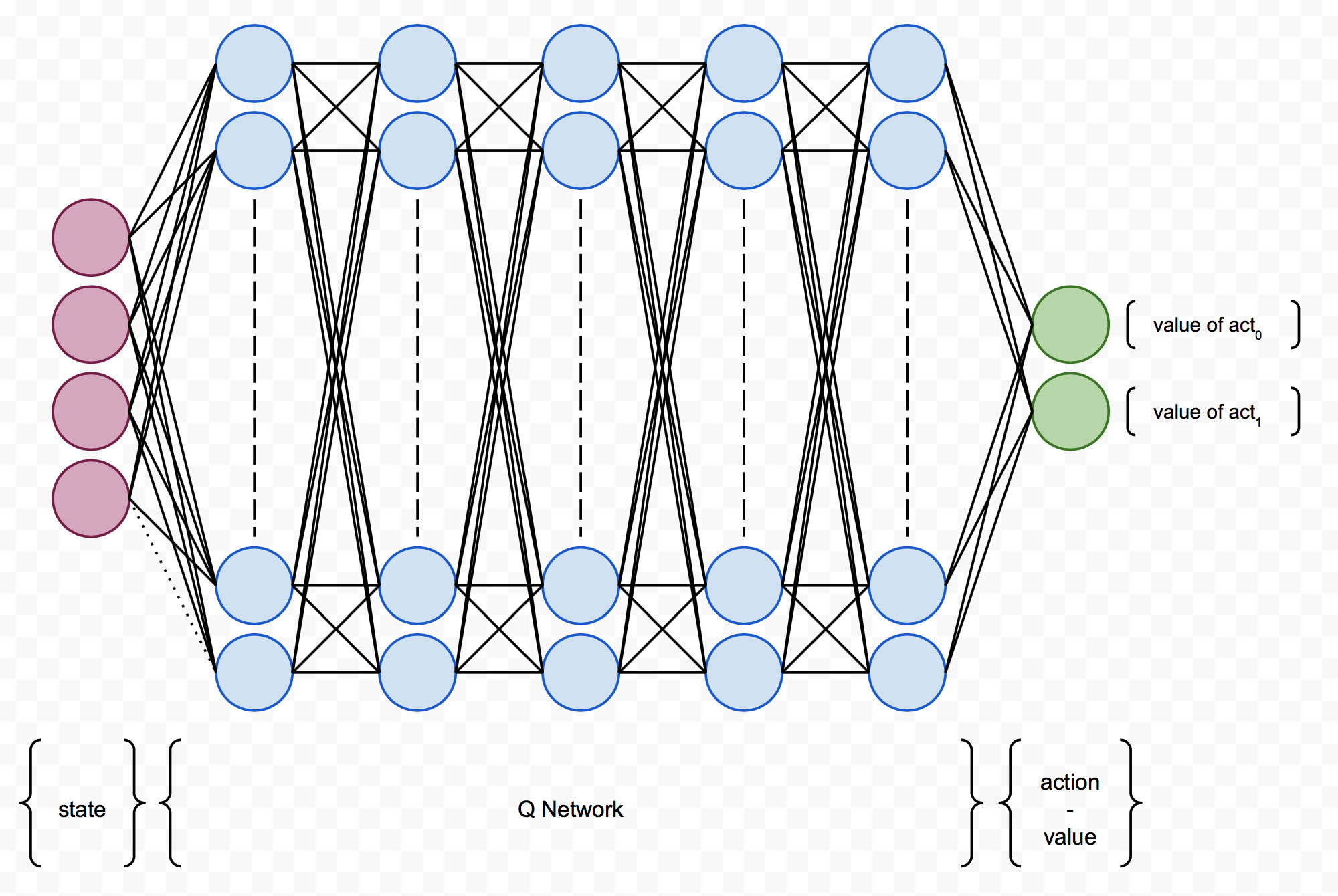
In Deepmind’s paper, they use convolutional neural networks to build the Q function because they want to use game screens as input (frame by frame). For the cart pole puzzle, there is only a 4 dimensions state so a normal neural network should work.
Setup the gym
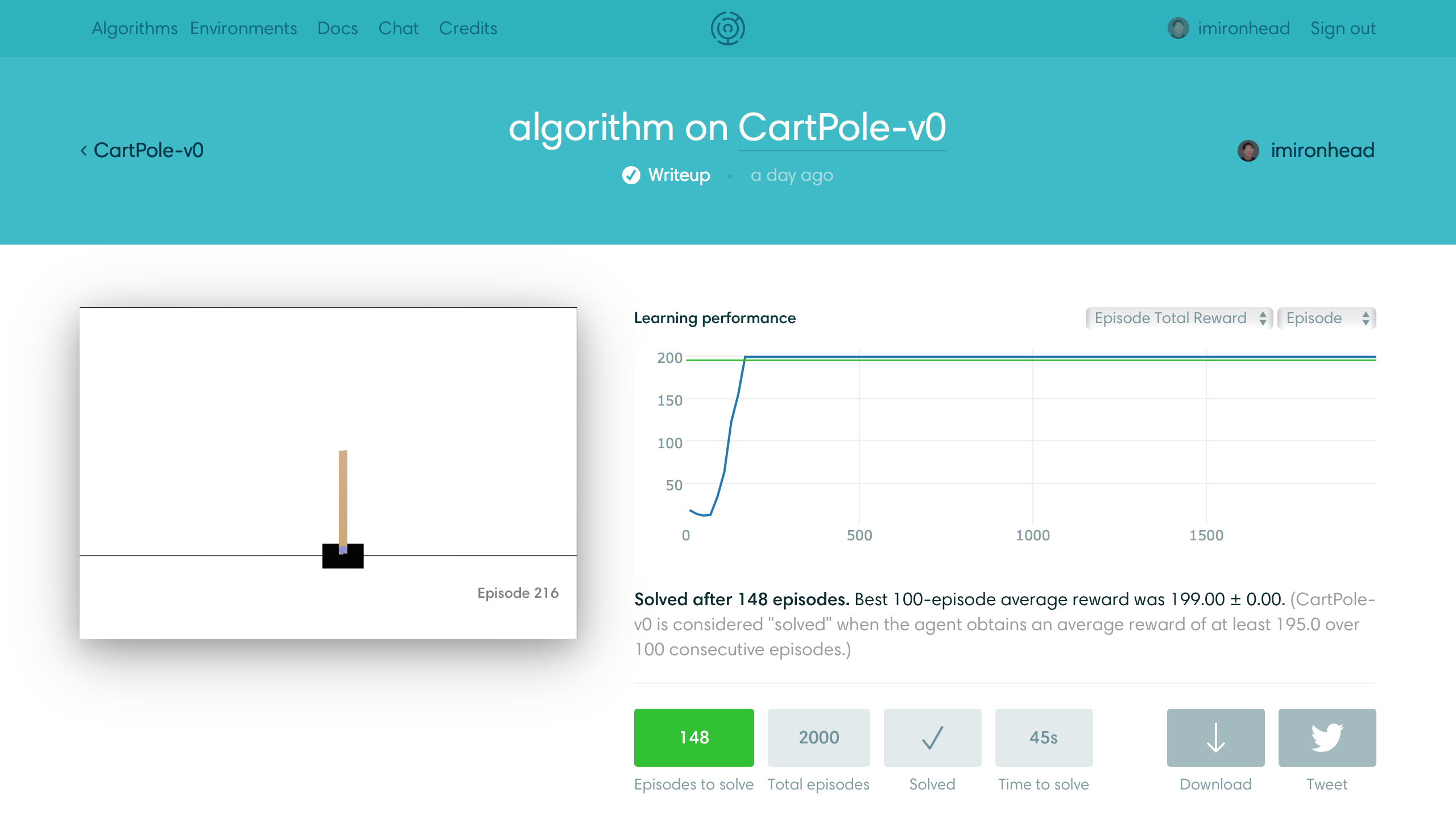
The scaffold of a gym challenge is to first build the environment. This one works on an environment named CartPole-v0. An episode is like a round in typical video action-fighting games. In the challenge, we want to keep the pole on the cart as long as possible. I wish I can solve it in 2000 episodes so that is my outer loop. Each episode starts with an initial state (observation) when the environment is reset. The state is 4 floating point numbers in this challenge, we do not know the meaning of this 4 values and that’s why reinforcement learning amazing: we are trying to solve a general problem! I guess they are the position, velocity, angle and angular velocity, but it doesn’t matter. In each step, we tell the environment the action we want to take (in this challenge, the actions are to push right/left). An episode is ended if done is true (either cart position or angle is outside of a certain range). Our goal is to find the best action for every step to get most rewards.
# Setup the environment
env = gym.make('CartPole-v0')
for episode in xrange(2000):
observation, reward, done = env.reset(), 0.0, False
for step in xrange(200):
action = agent.act(observation, reward, done)
observation, reward, done, _ = env.step(action)We want to implement an agent which decide action base on previous observations. In the beginning, we want the agent to learn something. So there is the epsilon. In the beginning, the probability is high to make the agent learn. The probability then decays over episodes which make the agent try to act base on the experience (what it has learned). And that’s it. All we need now is how to find a good action base on experience.
self._time += 1
if self._time % self._epislon_decay_time == 0:
self._epislon *= self._epislon_decay_rate
if np.random.rand() > self._epislon:
states = np.array([observation])
# calculate action-value pairs for the state
action_values = self._tf_action_value_predict.eval(
feed_dict={self._tf_prev_states: states})
# find the action that has the highest value.
action = np.argmax(action_values)
else:
# live and learn.
action = self._action_space.sample()Implement DQN
Keep the experience in D for replay. For each step, we take prev_action at prev_state, got a reward and move to next_state. All these 4 parameters give us an experience. We’ll keep them in numpy matrices for training. Besides, I am not rich and I do not have that much RAM. So I only keep some experiences and replace old ones randomly once the pool is full.
def create_experience(self, prev_state, prev_action, reward, next_state):
"""
keep an experience for later training.
"""
if self._experiences_num >= self._experiences_max:
idx = np.random.choice(self._experiences_max)
else:
idx = self._experiences_num
self._experiences_num += 1
self._experiences_prev_states[idx] = np.array(prev_state)
self._experiences_next_states[idx] = np.array(next_state)
self._experiences_rewards[idx] = reward
self._experiences_actions_mask[idx] = np.zeros(self._dim_action)
self._experiences_actions_mask[idx, prev_action] = 1.0Use tensorflow to build the neural work. For each experience, we have:
suppoe prev_action is $a_1$, then we wnat to minimize $L$ with L2 loss:
w1 = tf.random_uniform([self._dim_state, 128], -1.0, 1.0)
w1 = tf.Variable(w1)
b1 = tf.random_uniform([128], -1.0, 1.0)
b1 = tf.Variable(b1)
# omit w2, b2, w3, b3 :)
w4 = tf.random_uniform([128, self._dim_action], -1.0, 1.0)
w4 = tf.Variable(w4)
b4 = tf.random_uniform([self._dim_action], -1.0, 1.0)
b4 = tf.Variable(b4)
# Q for prev_states
prev_states = tf.placeholder(tf.float32, [None, self._dim_state])
hidden_1 = tf.nn.relu(tf.matmul(prev_states, w1) + b1)
hidden_2 = tf.nn.relu(tf.matmul(hidden_1, w2) + b2)
hidden_3 = tf.nn.relu(tf.matmul(hidden_2, w3) + b3)
prev_action_values = tf.squeeze(tf.matmul(hidden_3, w4) + b4)
prev_action_masks = \
tf.placeholder(tf.float32, [None, self._dim_action])
prev_values = tf.reduce_sum(
tf.mul(prev_action_values, prev_action_masks), reduction_indices=1)
# Q for next_states
prev_rewards = tf.placeholder(tf.float32, [None, ])
next_states = tf.placeholder(tf.float32, [None, self._dim_state])
hidden_1 = tf.nn.relu(tf.matmul(next_states, w1) + b1)
hidden_2 = tf.nn.relu(tf.matmul(hidden_1, w2) + b2)
hidden_3 = tf.nn.relu(tf.matmul(hidden_2, w3) + b3)
next_action_values = tf.squeeze(tf.matmul(hidden_3, w4) + b4)
next_values = prev_rewards + self._gamma * \
tf.reduce_max(next_action_values, reduction_indices=1)
# L2 loss
loss = tf.reduce_mean(tf.square(prev_values - next_values))
# minimize the L2 loss
training = tf.train.AdamOptimizer(1e-4).minimize(loss)Start training and watch the improvement of the policy. If everything goes fine, the loss will be minimized and the $Q$ will work better and better. Eventually, the $Q$ is better enough and make good decisions for the agent. Then the challenge is solved!
def train(self):
"""
train the deep q-learning network.
"""
# start training only when there are enough experiences.
if self._experiences_num < self._experiences_max:
return
# random batch for training.
ixs = np.random.choice(
self._experiences_max, self._batch_size, replace=True)
fatches = [self._tf_loss, self._tf_training]
feed = {
self._tf_prev_states: self._experiences_prev_states[ixs],
self._tf_prev_action_masks: self._experiences_actions_mask[ixs],
self._tf_prev_rewards: self._experiences_rewards[ixs],
self._tf_next_states: self._experiences_next_states[ixs]
}
# minimize loss to optimize the hyper parameters
loss, _ = self._tf_session.run(fatches, feed_dict=feed)Things I have learned from this challenge
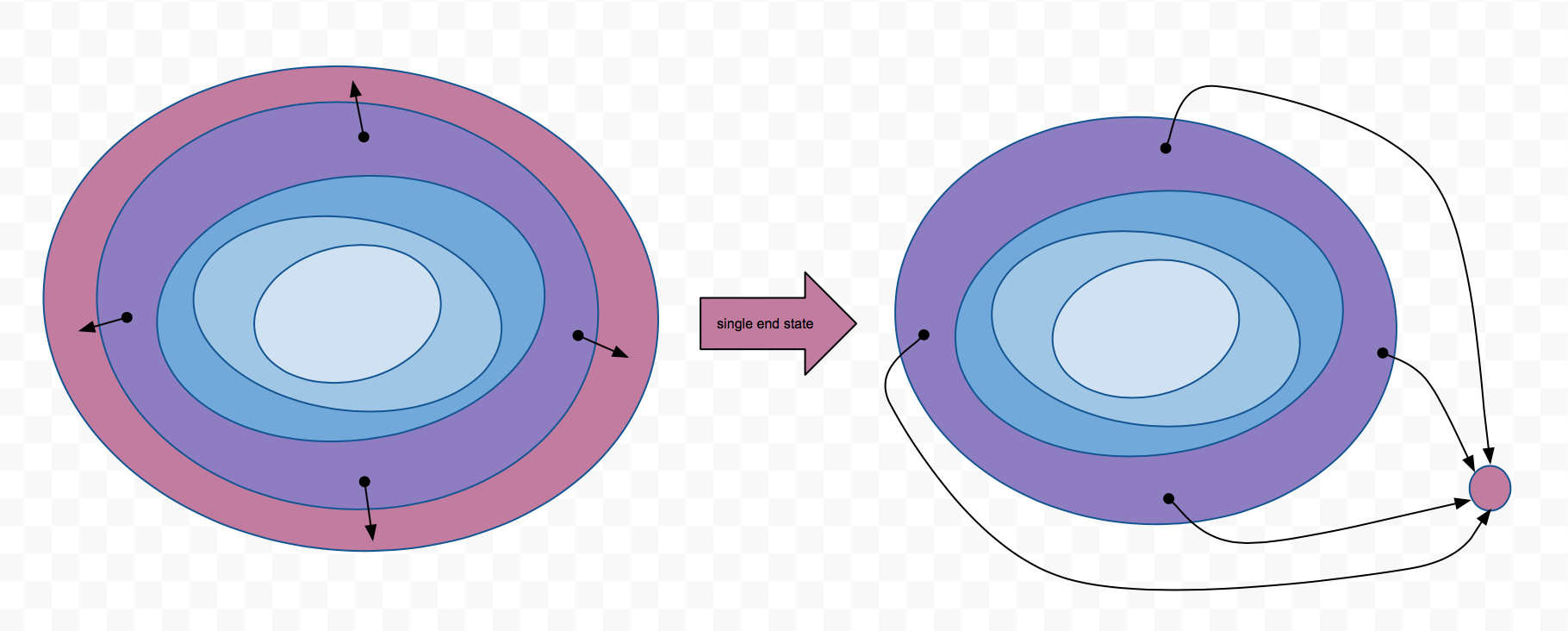
- I need the null endpoint. I had used ending states from the environment directly and got a worse result before the final implementation. Then I found Li Bin’s implementation who use null point. I thought it’s ok if I have lots of RAMs to keep bad ending in experiences. However, I am not rich. So instead of training an ending state sphere, make all bad states ended in a single point (zeros).
-
The last reward does not make sense, but we need to tune the rewards function anyway. The gym environment always returns 1.0 as a reward even when the episode is failed. To provide penalties for failed cases, we can set the reward to a value less than 0.0. Since the bad ending state is set to zeros, $Q$ for the ending state always gives us 0.0 state-action pairs which introduce nothing. Minus rewards help $Q$ to learn faster (to stay away from ending state as long as possible). Besides the punishment, we will get a good $Q$ eventually which can give us rewards better than 200 points. Notice that the environment would end the episode at most 200 steps if it’s in monitoring mode. Remember not to punish that kind of cases :).
-
I keep 10% of failed states explicitly to make the training stable.
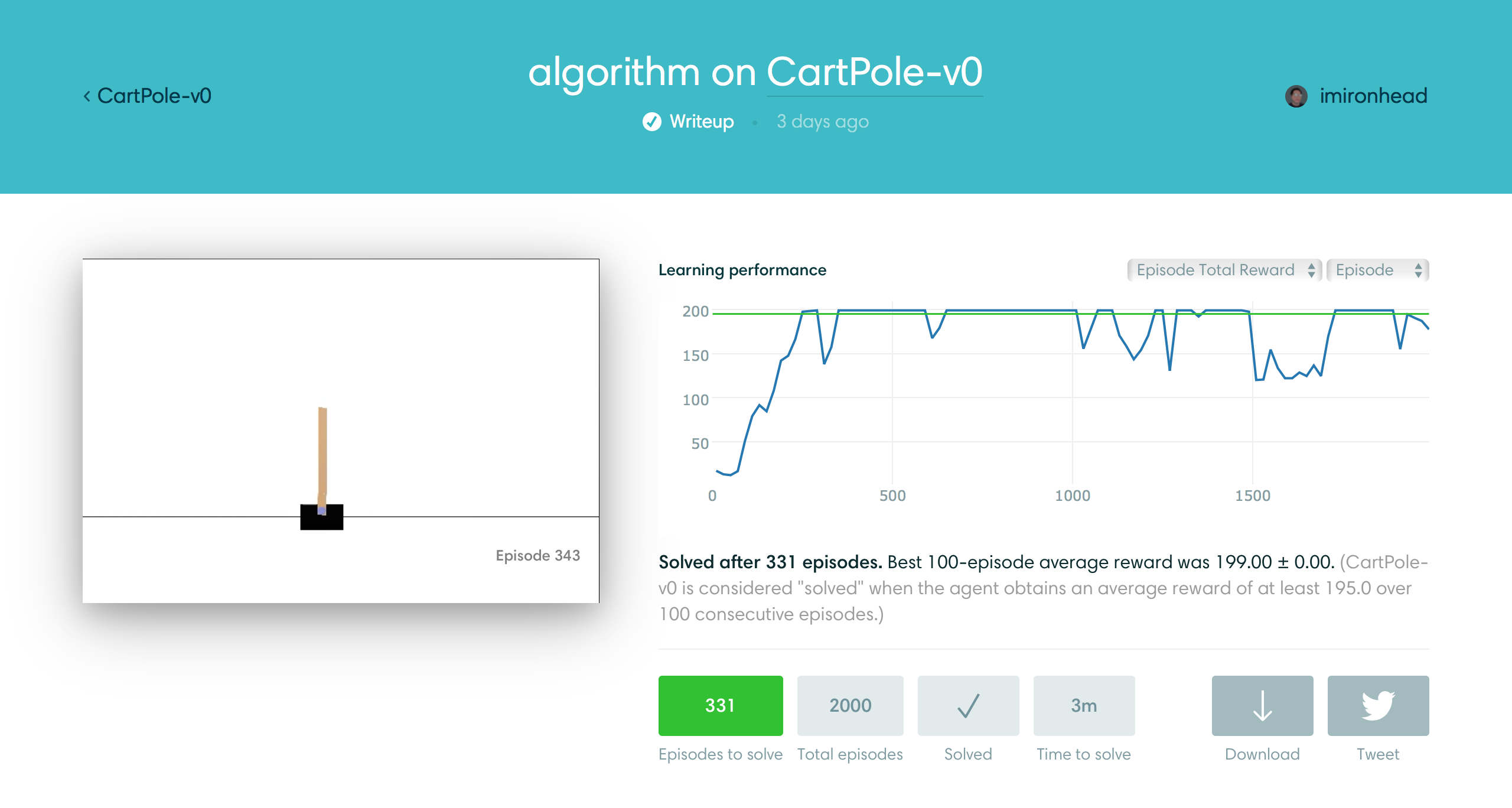 This is a result of old implementation. The average reward is not stable. It is because when we almost there and starts to play lots of good episodes whose rewards are better than 200. The results with punishment would be removed entirely from limited experience pool. After that, we do not have data to constrain the $Q$ for bad states. The $Q$ becomes worse and worse, provide worse decisions and the rewards drop suddenly. The new fail case then becomes an experience and $Q$ will be trained again. To solve the problem, I try to keep some bad experience explicitly (90%):
This is a result of old implementation. The average reward is not stable. It is because when we almost there and starts to play lots of good episodes whose rewards are better than 200. The results with punishment would be removed entirely from limited experience pool. After that, we do not have data to constrain the $Q$ for bad states. The $Q$ becomes worse and worse, provide worse decisions and the rewards drop suddenly. The new fail case then becomes an experience and $Q$ will be trained again. To solve the problem, I try to keep some bad experience explicitly (90%):
# in create_experience()
if self._experiences_num >= self._experiences_max:
# make sure we always have some penalties.
a = self._experiences_max * 9 / 10
b = self._experiences_max - a
if reward > 0.0:
idx = np.random.choice(a)
else:
idx = np.random.choice(b) + a
else:
idx = self._experiences_numMove toward next challenge
This is it. It’s very interesting and I am very excited that I have solved this challenge. I will find another one and try to conquer it with different algorithms (maybe policy gradient?). I wish this post is good enough to help newcomers. Let’s Go!