Monte Carlo Algorithm
Why I want to share Monte Carlo algorithm in KKStream
Alpha Go has won 4 games against Lee Sedol who is a world class Go master. I knew this would happen someday but did not expect it so soon! Now almost all software guys know names of the 2 algorithms: neural networks and Monte Carlo. For programmers, it’s not difficult to get a rough idea of how hard it is to play Go with brute force methods. And I always think it’s a good idea to help others explore different algorithms. So I decided to give a talk about MCTS in KKStream.
What happened to computer Go
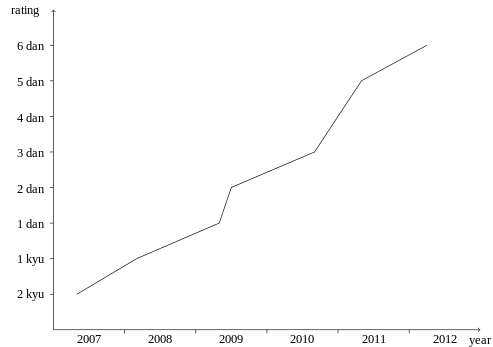
I was a ~1d Go player in 2000. There was a very good computer Go A.I. “Hand Talk” during that years. But even I could beat it easily. But things started to change. This chart presents the rating of Go program on KGS server. Now the program can beat me easily :).
In my opinion, there are 2 major problems in computer Go:
There are too many branches to build a game tree. Considering there are 3 states in each position (black, white and empty), there are $3^{361}$ possible games! And the size of the board is not considered yet! Professional players play games on a 19 x 19 board. But the general rule is able to work on boards with different size, e.g. a 38 x 38 boards. The strategy would be changed to play on the larger board. But world class players will still be world class while the larger game tree needs Moore’s Law.
Go players play game with some kind of sense. Go players usually play games with their sense. Even professional players would state: “I chose the move because I thought it would be interesting”. Besides, good players can guess the potential of stone groups, but it’s difficult to express it in algorithms (I don’t even know how).
Monte Carlo is a heuristic algorithm which was developed to solve the first problem: since I am not sure which one is the best, I wager on the most promising one! (Monte Carlo methods are also developed in many other areas, e.g. photon map of computer graphics)
Why reversi
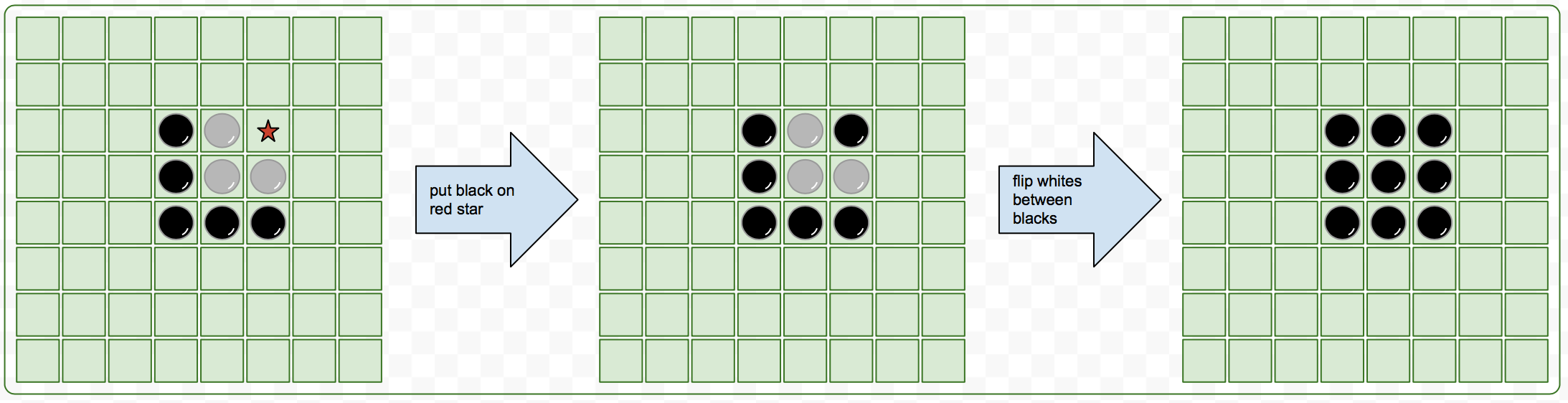
I use a board game ‘reversi’ to demo the algorithm because of many advantages:
- The rule is simple (wiki).
- The size of the game tree is reasonable.
- It’s famous on an old dictionary device in Taiwan.
- There are simple strategies to follow.


Vanilla Monte Carlo Algorithm
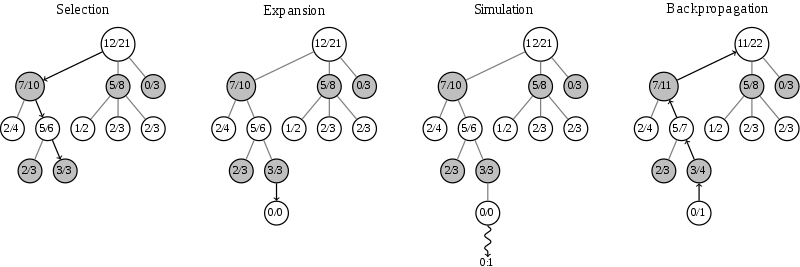
The algorithm is about how to search in a game states tree. In every state (tree node), a player can have several different moves (branches). There are 4 steps in each episode of Monte Carlo algorithm:
- Selection. An episode always begins at current state (the root of the tree). We want to select a child state with good quality (we call the quality “value”). For example, the 3 children states of root node have values 7/10, 5/8 and 0/3. The highest value is 7/10 so we select it. Keep doing this until we reach a state which has no child states (3/3). Now take a look at the second layer of the tree which is opponent’s turn, why we select the highest value for the opponents? Because we think they are smart and alway make good decisions :).
- Expansion. From the selected state, we enumerate possible states and choose a random one as selected state (if the state is not an ending, leaf).
- Simulation. Play a game from the selected state base on some policy (a random game is ok) and take the result.
- Backpropagation. Travel from selected state to root state. Update values of states on the path base on the simulated result. Intuitively, all states on the path are good if we win the simulated game.
The structure of a state in reversi looks like:
- Positions of black stones. (The states can be less due to symmetry. But I’m lazy :))
- Positions of white stones.
- Whose turn.
UCT the selection formula
During back propagation, we can update values base on any different formula. The formula I use to demo is “Upper Confidence Tree”. The variables are:
- $n_i$ : how many times we have visited this state (selection path).
- $w_i$ : how many times we have won through this state (simulation).
- $t$ : how many times we have visited parent of this state.
- $c$ : constant.
There are 2 features for this formula:
- Exploitation. We want to make sure a good decision is really good. So we invest computing power on promising decisions. $\frac{w_i}{n_i}$ is made for this. It contributes large value if we win many games through this state.
- Exploration. We want to make sure a bad decision is really bad. So we invest computing power on less visited states. $\sqrt{\frac{\ln t}{n_i}}$ is made for this. If the stats were visited less and lost most of the simulated game, give it a chance.
Combining the 2 features and tuning the constant factor give us better balance on Monte Carlo algorithm. Keep optimizing the game tree till we are satisfied. Then choose the child state which has been visited most! It’s good enough cause we invested most computing powers to make sure it’s good. It’s also stable enough cause we invested computing powers on the other states and they are no better.
How to implement it in C++
The core of MTCS for every episode: select, expand, simulate and backpropagate. If we need a stronger program, increase episodes. More episodes make the program more stable!
State* UpperConfidenceTree::Search(State* root) const {
shared_ptr<State> temp(root->Clone());
State* selected = nullptr;
for (int32_t round = 0; round < this->count_round_; ++round) {
selected = temp->Select();
if (selected->IsNormal()) {
selected = selected->Expand();
}
auto winner = selected->Simulate();
selected->Backpropagate(winner);
}
return temp->BestMove();
}Traverse the game state tree from current state till we reach a leaf state. In each depth, select the state with the highest value.
State* State::Select() {
// If there are no more moves, return this.
// If there are no children, return this to expand.
if (this->IsEnd() || this->children_.empty()) { return this; }
auto selected = max_element(
this->children_.begin(),
this->children_.end(),
[](const State* a, const State* b) -> bool {
return a->value_ < b->value_;
});
return (*selected)->Select();
}If the game is not ended in the selected state, enumerate its’ child states and pick one. Let a new state has maximum value to make sure all states are visited at least once.
State* ReversiState::Expand() {
auto moves = this->EnumValidMoves(this->player_);
if (moves.empty()) {
// This state is not an end and there is no move for this->player_.
// The player of this state should be flipped then.
auto state = dynamic_cast<ReversiState*>(this->Clone());
state->parent_ = this;
state->MoveAt(-1, -1);
this->children_.emplace_back(state);
} else {
for (auto move : moves) {
auto state = dynamic_cast<ReversiState*>(this->Clone());
state->parent_ = this;
state->MoveAt(move.x, move.y);
this->children_.emplace_back(state);
}
}
return this->children_.front();
}Play a random game and return the winner.
int32_t ReversiState::Simulate() {
shared_ptr<State> state_clone(this->Clone());
auto state = dynamic_pointer_cast<ReversiState>(state_clone);
while (state->IsNormal()) {
auto moves = state->EnumValidMoves(state->player_);
if (moves.empty()) {
state->MoveAt(-1, -1);
} else {
auto move = moves[rand() % moves.size()];
state->MoveAt(move.x, move.y);
}
}
return state->Winner();
}Update values of all states along the visited path.
void ReversiState::Backpropagate(int32_t winner) {
this->count_visits_ += 1.0f;
this->count_wins_ += (this->player_ == winner ? 0.0f : 1.0f);
if (this->parent_ != nullptr) {
auto parent = dynamic_cast<ReversiState*>(this->parent_);
for (auto child : parent->children_) {
auto the_child = dynamic_cast<ReversiState*>(child);
if (the_child->count_visits_ == 0.0f) { continue; }
float exploitation = the_child->count_wins_ / the_child->count_visits_;
float exploration = sqrt(
2.0f * log(parent->count_visits_ + 1.0f) / the_child->count_visits_);
the_child->value_ = exploitation + exploration;
}
parent->Backpropagate(winner);
}
}Demonstrate the values of states
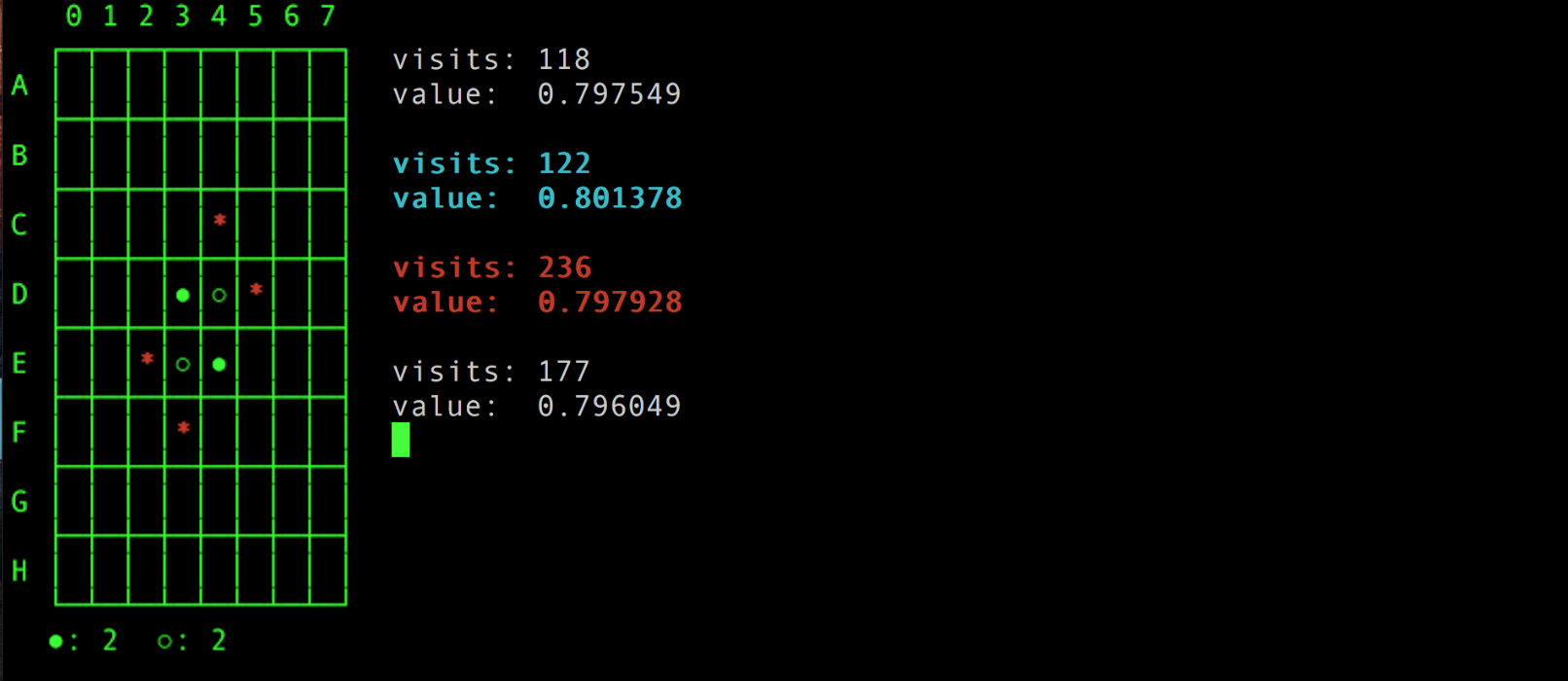
I also implemented a program to demo the value function (UCT). Keep evaluating the initial states and observe the values, the values of 4 possible moves will become close eventually. (cyan text for the best value, red text for most visited state)
Conclusion
One of the reasons I chose reversi is “there are simple strategies to follow”. But why? I have a simple strategy for this game: try to occupy the side/corner positions before the opponent. Because they are hard to be attacked, especially the corner. Now I have introduced the algorithm without any strategy (domain knowledge) and that is why I am excited: it’s for general purpose!
Reference
- My implementation on GitHub.
- Image: AlphaGo v.s. Lee Sedol
- Image: Steps of Monte Carlo tree search (Mciura / CC BY-SA 3.0)
- Image: Computer Go Ratings (Mciura / CC BY-SA 3.0)
.svg){kind=link}
{kind=link}